服務機器人以服務為目的,因此人們需要一種更方便、更自然、更加人性化的方式與機器人交互,而不再滿足于復雜的鍵盤和按鈕操作。基于聽覺的人機交互是該領域的一個重要發展方向。目前主流的語音識別技術是基于統計模式。然而,由于統計模型訓練算法復雜,運算量大,一般由工控機、PC機或筆記本來完成,這無疑限制了它的運用。嵌入式語音交互已成為目前研究的熱門課題。
嵌入式語音識別系統和PC機的語音識別系統相比,雖然其運算速度和內存容量有一定限制,但它具有體積小、功耗低、可靠性高、投入小、安裝靈活等優點,特別適用于智能家居、機器人及消費電子等領域。
1 模塊整體方案及架構
語音識別的基本原理如圖1所示。語音識別包括兩個階段:訓練和識別。不管是訓練還是識別,都必須對輸入語音預處理和特征提取。訓練階段所做的具體工作是通過用戶輸入若干次訓練語音,經過預處理和特征提取后得到特征矢量參數,最后通過特征建模達到建立訓練語音的參考模型庫的目的。而識別階段所做的主要工作是將輸入語音的特征矢量參數和參考模型庫中的參考模型進行相似性度量比較,然后把相似性最高的輸入特征矢量作為識別結果輸出。這樣,最終就達到了語音識別的目的。
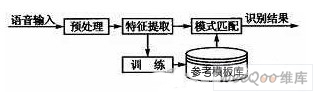
圖1 語音識別的基本原理
現有的語音識別技術按照識別對象可以分為特定人識別和非特定人識別。特定人識別是指識別對象為專門的人,非特定人識別是指識別對象是針對大多數用戶,一般需要采集多個扁平型電感差模電感人的語音進行錄音和訓練,經過學習,達到較高的識別率。
基于現有技術開發嵌入式語音交互系統,目前主要有兩種方式:一種是直接在嵌入式處理器中調用語音開發包;另一種是嵌工字電感器入式處理器外圍擴展語音芯片。第一種方法程序量大,計算復雜,需要占用大量的處理器資源,開發周期長;第二種方法相對簡單,只需要關注語音芯片的接口部分與微處理器相連,結構簡單,搭建方便,微處理器的計算負擔大大降低,增強了可靠性,縮短了開發周期。
語音識別技術在國內外的發展十分迅速。目前國內在PC應用領域,具有代表性的有:科大訊飛的InterReco2.0、中科模式識別的Pattek ASR3.0、捷通華聲的jASRv5.5;在嵌入式應用領域,具有代表性的有:凌陽的SPCE061A、ICRoute的LD332X、上海華鎮電子的WS-117。
本文的語音識別方案是以嵌入式功率電感器微處理器為核心,外圍加非特定人語音識別芯片及相關電路構成。語音識別芯片選用ICRoute公司的LD33 20芯片。
2 硬件電路設計
如圖2所示,硬件電路主要包括主控核心部分和語音識別部分。語音進入語音識別部分后,將處理過的數據并行傳輸到主控制器,主控制器經過處理后,發送命令數據到USART,USART可用于擴展外圍串行設備,如語音合成模塊等。
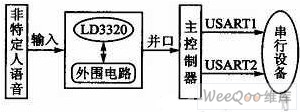
圖2 硬件電路
2.1 語音識別電路
圖3為語音識別部分原理圖,參照了ICRoute發布的LD3320數據手冊進行設計。LD3320的內部集成了快速穩定的優化算法,不需外接Fla-sh、RAM,不需要用戶事先訓練和錄音而完成非特定人語音識別,識別準確率高。
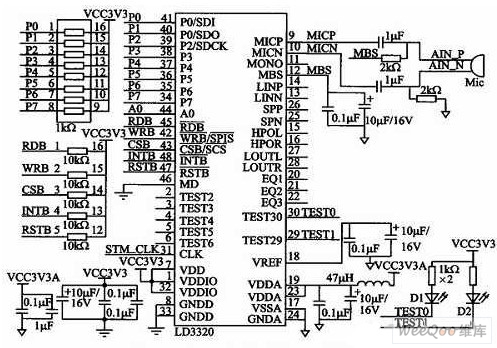
圖3 語音識別部分原理圖
圖中,LD3320采用并行方式直接與STM32F103C8T6相接,均采用1kΩ電阻上拉,A0用于判斷是數據段還是地址段;控制信號