


2003年發布的H.264視頻壓縮編碼標準在一定程度上解決了要在盡可能低的碼率下獲得盡可能好的圖像質量這一問題。在相同的重建圖像質量下,H.264能夠比H.263節約50%左右的比特率。此外,H.264還增強了其對網絡的適應性,差錯的恢復能力,使其非常適用于數字視頻存儲、IPTV及手機電視等視頻質量要求高而信道傳輸環境不穩定的場合。
由于加入了多模式位移估計、基于4×4塊的整數變換等多種新的算法,使H.264算法本身的復雜度大幅增加。因此采用基于TI的TMS320DM6446的DAVINCI_EVM平臺作為算法的硬件平臺,提出針對達芬奇平臺對H.264編碼器進行優化,在不降低編碼質量的情況下提高程序運行效率,降低運算復雜度的一個實現方案。
H.264編碼器的算法流程
H.264編碼器結構如圖1所示,輸入的Fn為當前幀或場,編碼器以宏塊為單位進行處理,每個宏塊可以選擇幀內或者幀間預測兩種編碼方式。如果采用幀內編碼模式,其預測值PRED(圖1中為P)是由本幀中之前已經經過編碼、解碼、重建的一些樣本點生成。而如果采用幀間模式,則P由一個或者多個參考幀的運動補償預測生成。預測值P和當前塊相減后,產生一個殘差塊D,經塊變換、量化后產生一組量化后的變換系數X,再經熵編碼,與解碼所需的一些信息一起組成一個壓縮后的碼流,經NAL供傳輸和存儲用。
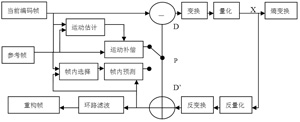
圖1 H.264編碼器結構
編碼硬件平臺概況
本設計采用的達芬奇數字視頻評估模塊DVEVM(Digital Video Evaluation Modul模壓電感濾波器電感e)是TI提供的用來評估DaVinci技術和DM644x體系架差模電感構的評估模塊,是強調片上能力的一個很好的參考平臺。其硬件資源包括TM320DM6446的DSP和ARM9的雙核芯片、128M的SDRAM、16MB的NAND Flash以及豐富的外設接口。
TM320DM6446中用于編碼器具體實現的C64x+DSP的時鐘頻率達到600MHz。C64x+DSP的內部存儲器的配置包括32KB的程序存儲器L1P、80KB的數據存儲器L1D和64KB的二級緩存L2。圖2為TM320DM6446中DSP端的核心C64x+的結構原理圖。
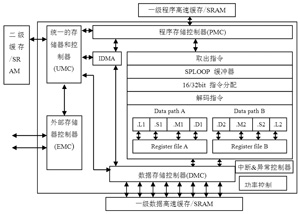
圖2 C64x+結構原理圖
編碼器在TM320DM6446上的實現
由于DSP平臺與PC平臺的差異性,必須要對PC上開發的編碼器程序進行結構上的調整,并進行合理的內存分配才能在DSP平臺上正常的運行。主要實現步驟如下。
1 編碼器C語言結構調整
PC平臺上用C語言實現的編碼器在DSP平臺上的編碼幀率(fps)非常低,平均2s才能編完一幀,其主要原因是無法利用DSP的并行處理機制。因此針對C64x+的特點,將程序中對流水線操作影響較大的循環拆分成若干小循環實現。對編碼器運行速度影響較大的模塊,如sad的計算,DCT變換等采用CCS自帶的圖像庫以提高編碼效率。
2 DSP端的內存配置
由于視頻一體電感編碼的數據存取量較大,而 DAVINCI_EVM提供了256M的外部存儲器DDR2,因此通過對DSP/BIOS的設置將外部存儲器設置為DDR2,并將可執行的C代碼及C代碼的堆存入外部存儲器中。
3 對DSP端BOOT的設置
由于TM320DM6446采用雙核的設計,ARM端只負責整個工程的控制而不參與編碼算法的具體實現。為了保證編碼算法能在DSP端無中斷的全速運行,需要對ARM端進行屏蔽,并通過對DAVINCI_EVM跳線的設置使DSP端自BOOT。
通過以上步驟,編碼器效率雖然有所提高,但仍無法滿足實時性的要求,因此必須結合DM6446本身的特點對編碼器算法進行進一步的優化。
編碼器的優化
本文對H.264算法的優化主要有兩個方面:1)對算法中耗時較多的運動估計模塊進行優化;2)對DSP的數據搬移進行優化。
1 對編碼器算法運動估計模塊的優化
由于DSP硬件資源有限,因此有必要對H.264編碼器中所耗時間較多的模塊進行優化,表1為H.264各模塊復雜度比較。
由表1可見,運動估計占了一半左右的時間。運動估計復雜度高的主要原因是采用了全搜索算法,雖然精度非常高,但帶來了大量的計算量。針對這一問題,本設計在已有的菱形搜索算法基礎上進行進一步的優化。
為了減少靜止宏塊被編碼以及大模板搜索所帶來的運算量,在用菱形算法進行運動搜索之前,以待編碼宏塊周圍已編碼宏塊的運動矢量信息及SKIP狀況為依據預測當前宏塊是否使用SKIP模式編碼。當待編碼宏塊為非靜止宏塊時,再根據周圍已編碼宏塊的SAD值預測當前宏塊的運動劇烈程度,若是運動平緩的宏塊則直接使用小模板進行搜索。只有當待編碼宏塊被判定為劇烈運動的宏塊時才進行大模板搜索。由于多次的大模板搜索循環帶來較大的計算量,因此在進行大模板搜索之前首先根據周圍宏塊的信息對最大搜索次數MaxNum進行預估一體電感器值。當大模板的搜索次數大于MaxNum時直接跳轉至小模板搜索。此流程設計可使靜止宏塊和運動平緩的宏塊不進入運算量大的大模板搜索環節。優化后的菱形算法流程如圖3所示。
大功率電感廠家 |大電流電感工廠
