


1引言
從20世紀50年代開始對語音識別的研究開始,經過幾十年的發展已經達到一定的高度,有的已經從實驗室走向市場,如一些玩具、某些部門密碼語音輸入等,隨著DSP和專用集成電路技術的發展,快速傅立葉變換以及近來嵌入式操作系統的研究,使得特定人識別尤其是計算量小的特定人識別成為可能。因此,對特定人語音識別技術在汽車控制上的應用的研究是很有前途的。
2 特定人語音識別的方法
目前,常用的說話人識別方法有模板匹配法、統計建模法、聯接主義法(即人工神經網絡實現)。考慮到數據量、實時性以及識別率的問題,筆者采用基于矢量量化和隱馬爾可夫模型(HMM)相結合的方法。
說話人識別的系統主要由語音特征矢量提取單元(前端處理)、訓練單元、識別單元和后處理單元組成,其系統構成如圖1所示。
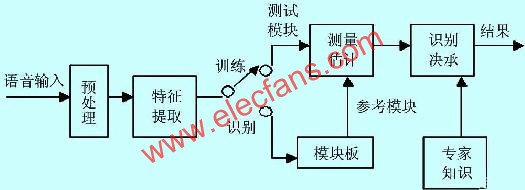
圖1系統構成
由上圖也可以看出,每個司機在購買車后必須將自己的語音輸入系統,也就是訓練過程,當然最好是在安靜、次數達到一定的數目。從此在以后駕駛過程中就可以利用這個系統了。
所謂預處理是指對語音信號的特殊處理:預加重,分幀處理。預加重的目的是提升高頻部分,使信號的頻譜變得平坦,以便于進行頻譜分析或聲道參數分析。用具有 6dB/倍頻程的提升高頻特性的預加重數字濾波器實現。雖然語音信號是非平穩時變的,但是可以認為是局部短時平穩。故語音信號分析常分段或分幀來處理。
2.1 語音特征矢量提取單元
說話人識別系統設計中的根本問題是如何從語音信號中提取表征人的基本特征。即語音特征矢量的提取是整個說話人識別系統的基礎,對說話人識別的錯誤拒絕率和錯誤接受率有著極其重要的影響。同語音識別不同,說話人識別利用的是語音信號中的說話人信息,而不考慮語音中的字詞意思,它強調說話人的個性。因此,單一的語音特征矢量很難提高識別率。該系統在說話人的識別中采用倒譜系數加基因周期參數,而在對控制命令的語音識別中僅采用倒譜系數。其中,常用的倒譜系數有2 種,即LPC(線性預測系數)和倒譜參數(LPCC),一種是基于Mel刻度的MFLL(頻率倒譜系數)參數(Mel頻率譜系數)。
對于LPCC參數的提取, 可先采用Durbin遞推算法、格型算法或者Schur遞推算法來求LPC系數,然后求LPC參數。設第l幀語音的LPC系數為αn,則LPCC的參數為![]() 1<n≤p
1<n≤p
其中p為LPCC系數的階數,k為LPCC系數的遞推次數。
進一步的研究發現,引入一階和二階差分倒譜可以提高識別率。
對于MPCC參數的提取,若根據Mel曲線將語音信號頻譜分為K個頻帶,每個頻帶的能量為θ(Mk),則 MFCC參數為 1<n≤p
1<n≤p
通過對LPCC和MFCC參數對識別率影響的實驗比較,筆者選取LPCC參數及其一階和二階差分倒譜稀疏作為大功率電感特征參數。
基音周期估計的方法很多,主要有基于求短時自相關函數的算法、基于求短時平均幅度差函數(AMDF)的算法、基于同態信號處理和線性預測編碼的算法。筆者僅介紹基于求短時自相關函數的算法。
設Sw(n)是一段加窗語音信號,它的非零區間為0<n≤n-1。Sw(n)的自相關函數稱為語音信號的S(n)的短時自相關函數,用Rw(l)表差模電感示,即Rw(電感生產廠家l)= 可知短時自相關函數在Rw(0)處最大,且在基音周期的各個整數倍點上有很大的峰值,選擇合適的窗函數(窗長為40ms的Hamming窗)與濾波器(帶寬為60~900Hz的帶通濾波器)后,只要找到自相關函數的第一最大峰值點的位置并計算電感器大小它與零點的距離,便能估計出基音周期。 大功率電感廠家 |大電流電感工廠
可知短時自相關函數在Rw(0)處最大,且在基音周期的各個整數倍點上有很大的峰值,選擇合適的窗函數(窗長為40ms的Hamming窗)與濾波器(帶寬為60~900Hz的帶通濾波器)后,只要找到自相關函數的第一最大峰值點的位置并計算電感器大小它與零點的距離,便能估計出基音周期。 大功率電感廠家 |大電流電感工廠
